


DataOps - Information Factory
Automate everything where the longterm value of automation out weighs the short term cost of creating the automation.

The problem is we treat all data as a bespoke product
«««state what the problem is and why we don’t think of data as a problem that can be solved using manufacturing and lean patterns»>
The Concept of a Data Architecture
«< tbd»>
Layered Data Architectures
«<1990s, 2000, hadoop/bigdata>
«< modern data stack mad person knitting>
«< medallion»
An Agile Data Information Factory
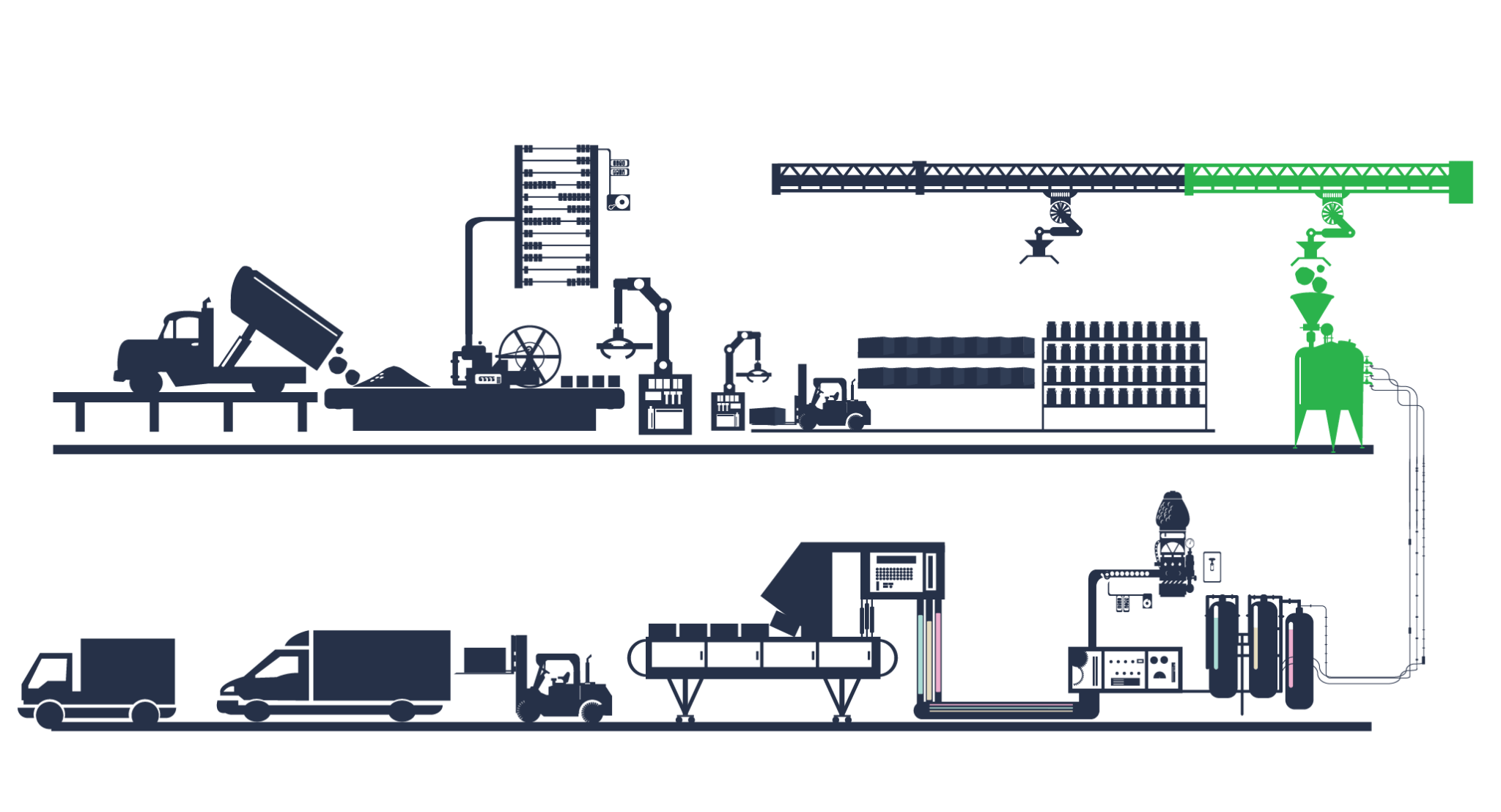
An Information Factory is focused on automating as many steps of the Information Value Stream as practically possible, streamlining the process for efficiency and productivity.
Think of it as the equivalent of an automated manufacturing factory, but for data.
It automates the process of collecting raw data, manufacturing it into valuable information, and delivering it to the customers who need it, removing the need for human involvement.
«<data platform factory vs information factory»
«corporate information factory book»
An Agile Data Factory Architecture
Layers in the data system

We use a multi-layer data architecture pattern to build a Data Factory that is flexible, scalable and adaptable.
The pattern introduces a series of layers into the Data Factory that separate data into modular components, each with prescribed input and output patterns.
A modular data system makes it easy to find and tackle data breakages, ensure the correct data is used for each purpose, and locate important stuff like calculated metrics.
Each layer performs its operations in isolation. The three patterns we adopt for the layers are the History layer, the Designed layer, and the Consume layer
History

In it goes!

The data is collected from Systems of Capture and loaded into the History layer as it arrives.
The quality, structure and type of the data isn’t important at this stage.
The objective is just to get the data into the Data Factory as fast as possible; subsequent data layers will handle quality and integration issues.

Taking stock

As the data arrives into the Data Factory we inspect it and tag it with additional data that will be useful later.
We tag the date it arrived, and we check it’s the data we expected to collect and in the format we expected it.
We scan the data and store the profile of the data with it. We look for any obvious anomalies or defects and flag them if we find them.

Rack & Stack


The collected data is stored in the History layer.
The History layer is immutable and remembers every change to the data for future reference so that trends can be observed; in effect it serves as the organisation’s memory, retaining a persistent copy of the data and its structure over time.
The data is stored in its original format, just as it was collected from the source applications.
Designed
Sort it out

In the Designed layer, data is sorted into Business Concepts, Detail and Events, applying business context.
This is the first layer in the data system where the data structure is changed.
We are beginning the work to make data understandable and to integrate the raw data that has been collected and stored.

Apply some colour?

Once the data has been separated into Business Concepts, Details and Events, business logic can be applied in the Designed layer to make the data more useful.
We may clean the data to make it fit for purpose, we may augment the data to created new inferred data values.
This is the first layer in the data system where the data values are manipulated if required.
We always have the History layer available to audit and view what the data originally looked like when it was captured.

Make it special

We change the data in the Designed layer to make it fit for our specific
business purpose.
We combine Business Concepts or Events to create a single view of this data.
We create metrics that make it easy to measure a business outcome on an ongoing basis.
Consume

Ship out
Once collected, validated, cleaned, augmented and combined, the data is delivered in a consumable format in the Consume layer.
The data format will be based on patterns which are simple and familiar to the end consumer. Typically, large wide tables or star schemas.
No further changes are made to the data values at this stage, but the structure is altered to suit the requirements of last mile tools.
This provides the last mile tools the right data, in the right format, in the right way.
Last Mile

At your service

Last Mile tools consume the data and deliver Information Products to consumers the way they prefer.

Some consumers prefer silver service, some prefer self-service, and some need the results of machine-driven models.
The last mile focusses on delivering information the way they want it and when they need it.