

“Arm Waves” are messy brain dumps, long form articles written to kickstart research, spark thinking, surface ideas and identify gaps, before they are eventually refined into a focused, curated set of “Finger Point” content, in a published “an Agile Data Guide”.
I often find writing helps me coalesce and refine my thoughts when new patterns start to emerge, but aren’t very clear yet.
This is the Arm Waves, aka brain dump / train of thought to help refine what I think the data stack looks like in the new “AI” domain.
I am iterating this article as I research and think about the patterns needed in this space, so the post will be updated overtime as I learn more.
Sections
Background to the pattern of the "Context Plane"
The new "AI Data Stack"
Defining the “AI” domain
Lets anchor the context of what I mean by the “AI” domain.
I am thinking about GenAI, Large Language Models (LLM’s), Agents, Agentic and MCP’s.
Lets pop over to my ChatGPT co-friend for definitions:
GenAI: Software that generates new content (text, images, code, etc.) based on patterns it has learned from large datasets, typically using AI models.
Large Language Models (LLMs): Advanced AI models trained on vast amounts of text data to understand and generate human-like language.
Agents: Software systems that use models like LLMs to autonomously perform tasks, often combining reasoning, decision-making, and interaction with tools or data.
Agentic: Describes behaviour or systems that act with initiative, making decisions and taking action toward goals.
MCP (Model Context Protocol): Provides a universal adapter for AI agents / LLMs to integrate and share data with external tools, systems, and data sources without custom coding. MCP is often referred to as “the USB-C of AI apps” .
Don’t love the definitions it came up with, but don’t hate them enough to spend time rewriting them (yet).
I’m not thinking about Data Mining, Statistics, Data Science, Machine Learning and all those patterns that I believe have been in the “Analytics” domain for many decades.
Defining the current data stack
Context is key so lets understand how I see the current data stack pattern.
I tend to think of patterns in layers.
So for me there is a very high level view where I distill the patterns down into as few large boxes as possible:
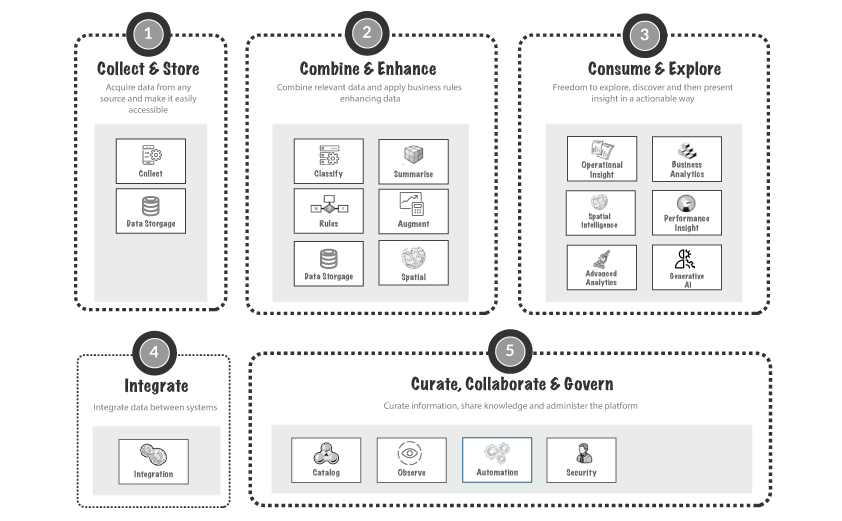
And then I will break that down into a lot of much smaller boxes when I need to define more detailed patterns:
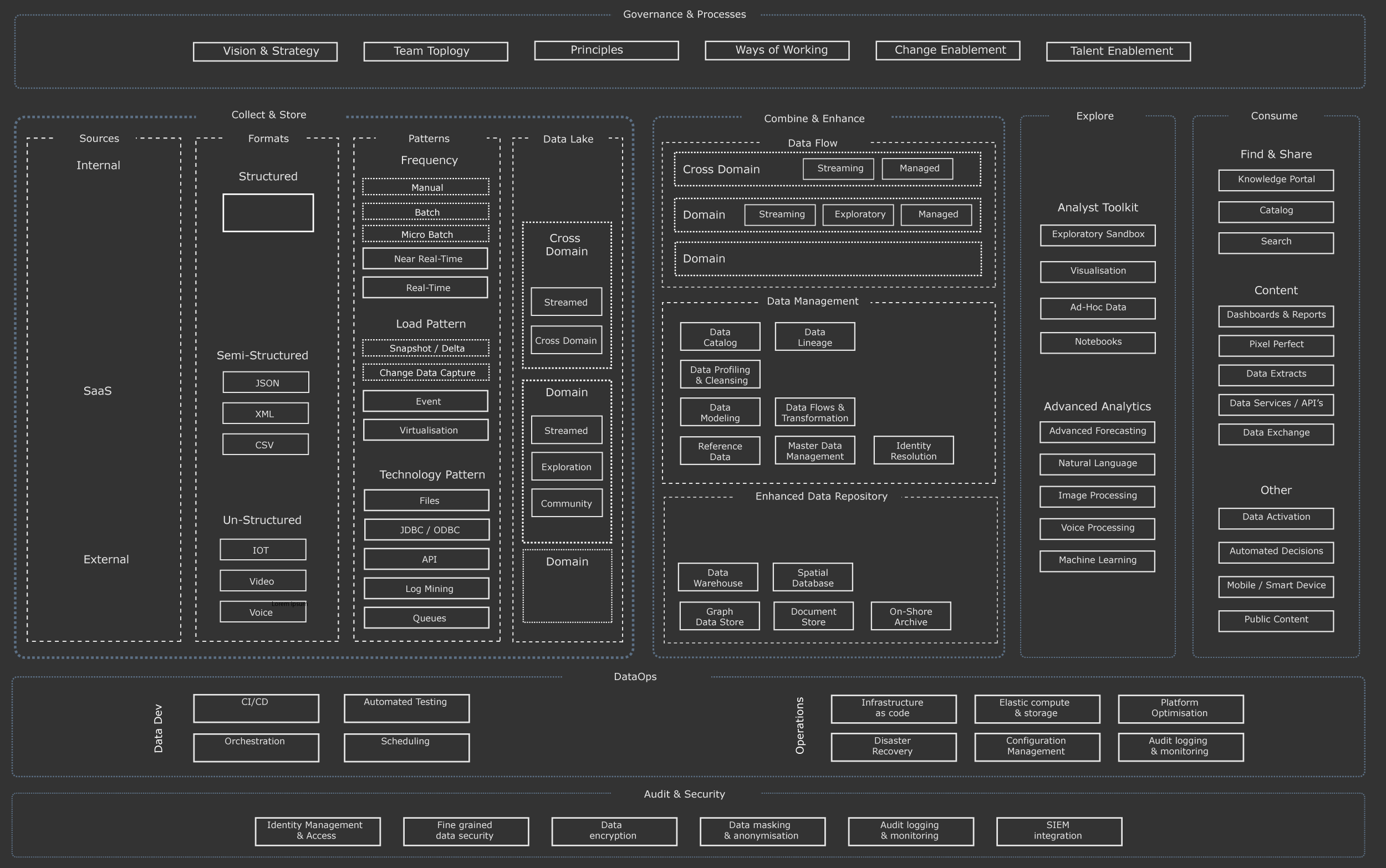
I have used both of these diagrams for a while now and they both need to be iterated for the “AI Data Stack” pattern.
I did an iteration a year or two ago where the core data “AI” pattern that was emerging was the Text to SQL pattern and so I added a box in the Consume areas to cover that.
But things have accelerated a lot in this space and I need to do another major iteration to my thinking and pattern library.
For this article I am going to call out a few core patterns that are helping my current train of thought on the patterns that need to be iterated the most.
Again when I am thinking about new patterns I find thinking in big boxes, not detailed ones helps, it stops me getting stuck in the weeds too early or stops me “boiling the ocean” as Juan Sequeda likes to say.
Centralised Data
The current data stack pattern is focussed on collecting data from source systems, storing that data in one place, changing the data to make it fit for purpose and then providing access to that data to any person or system who needs it.

Data platform(s) harvest the data from the places that create it. Last Mile tools consume the data from the data platform.
Catalogs harvest the Data / Metadata
The current data stacks are focussed on Catalog capabilities that extract the Metadata (and often data) from the various places that data is stored.
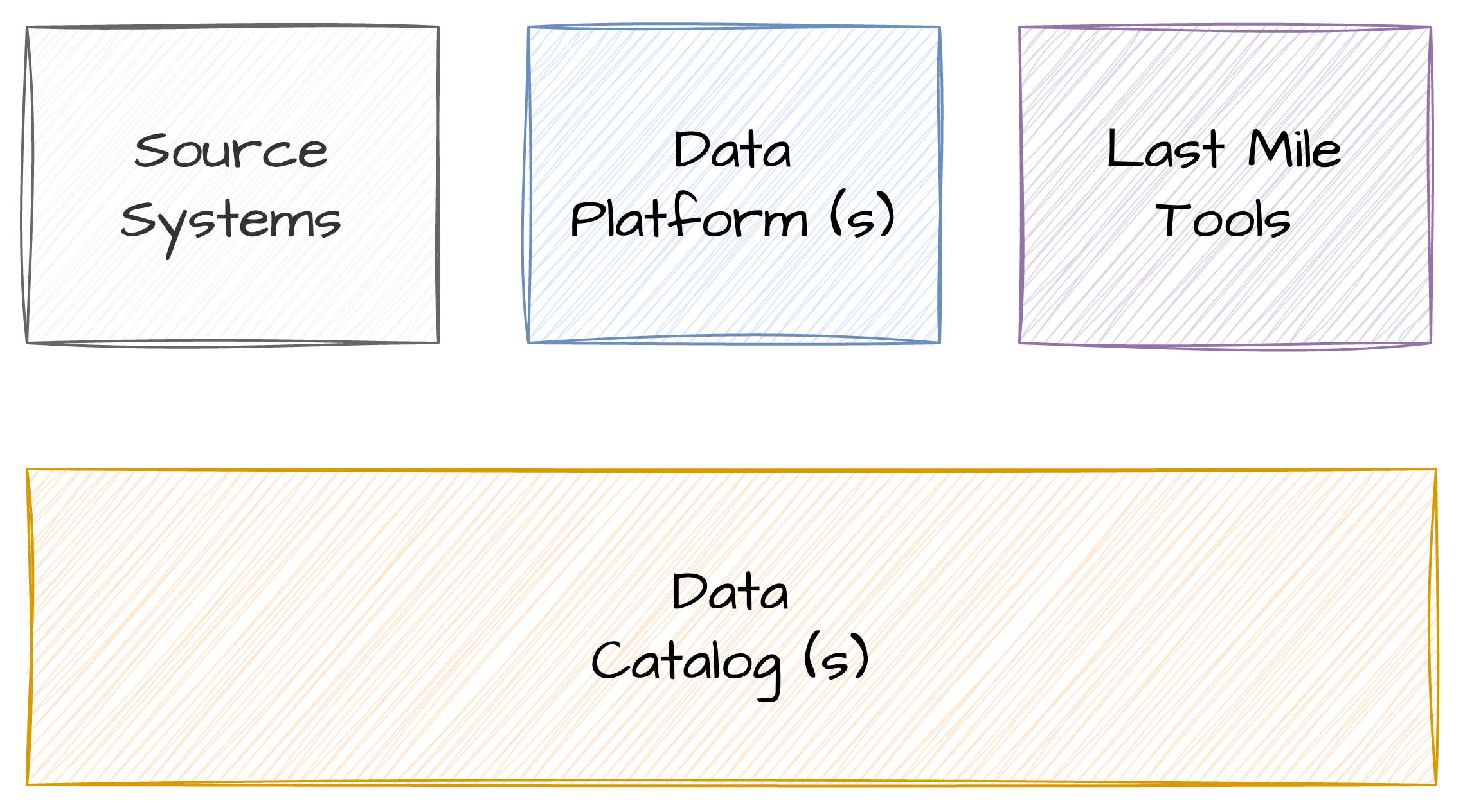
Catalog(s) harvest the metadata from the places that create it, after it has been created.
Defining the “AI Data Stack”
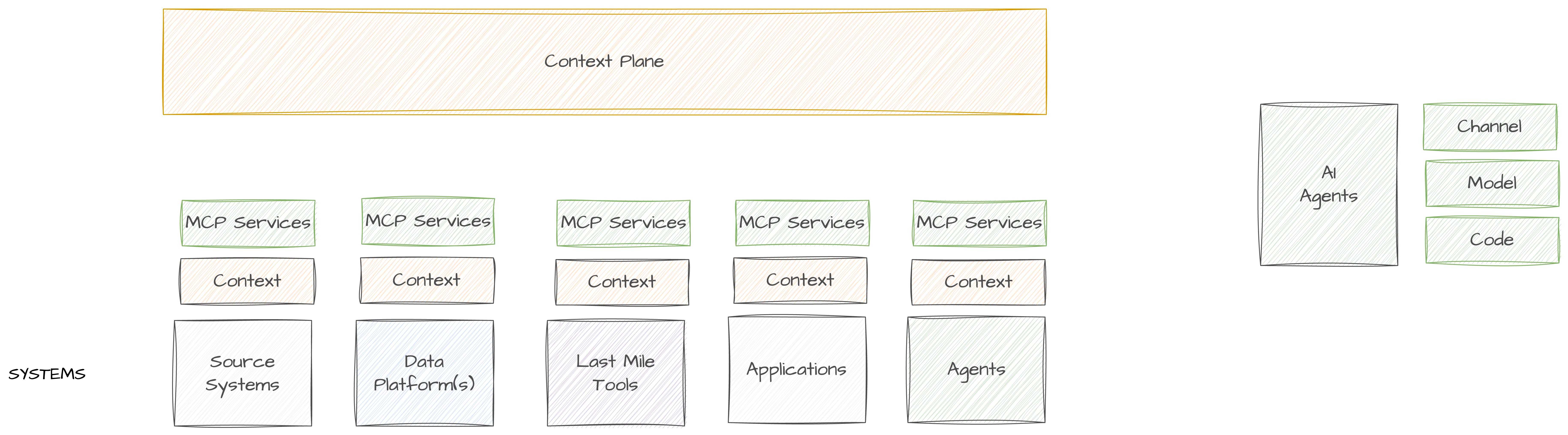
This diagram / map is a brain dump, my focus is the number of boxes and what they do / don’t do. Not the flow, or layout etc (yet).
Key patterns I am thinking about (in no particular order)
Source Systems are a source of Data and Context that the Agents need to understand and access;
Data Platforms are a source of Data and Context that the Agents need to understand and access, but not the only one anymore;
An Agent may invoke a Last Mile Tool, an action in an Application, or another Agent.
Source Systems and Applications are one in the same, but keeping them as separate in this diagram helps with the thinking process right now.
All the places that hold data, provide Context for that data to whatever needs that Context.
All the “SYSTEMS” / places that hold Data or have a User Interface, will provide a MCP service that allows an agent to access it directly, removing the need to always access the centralised data platform (this feels very much like the data virtualisation patterns of old).
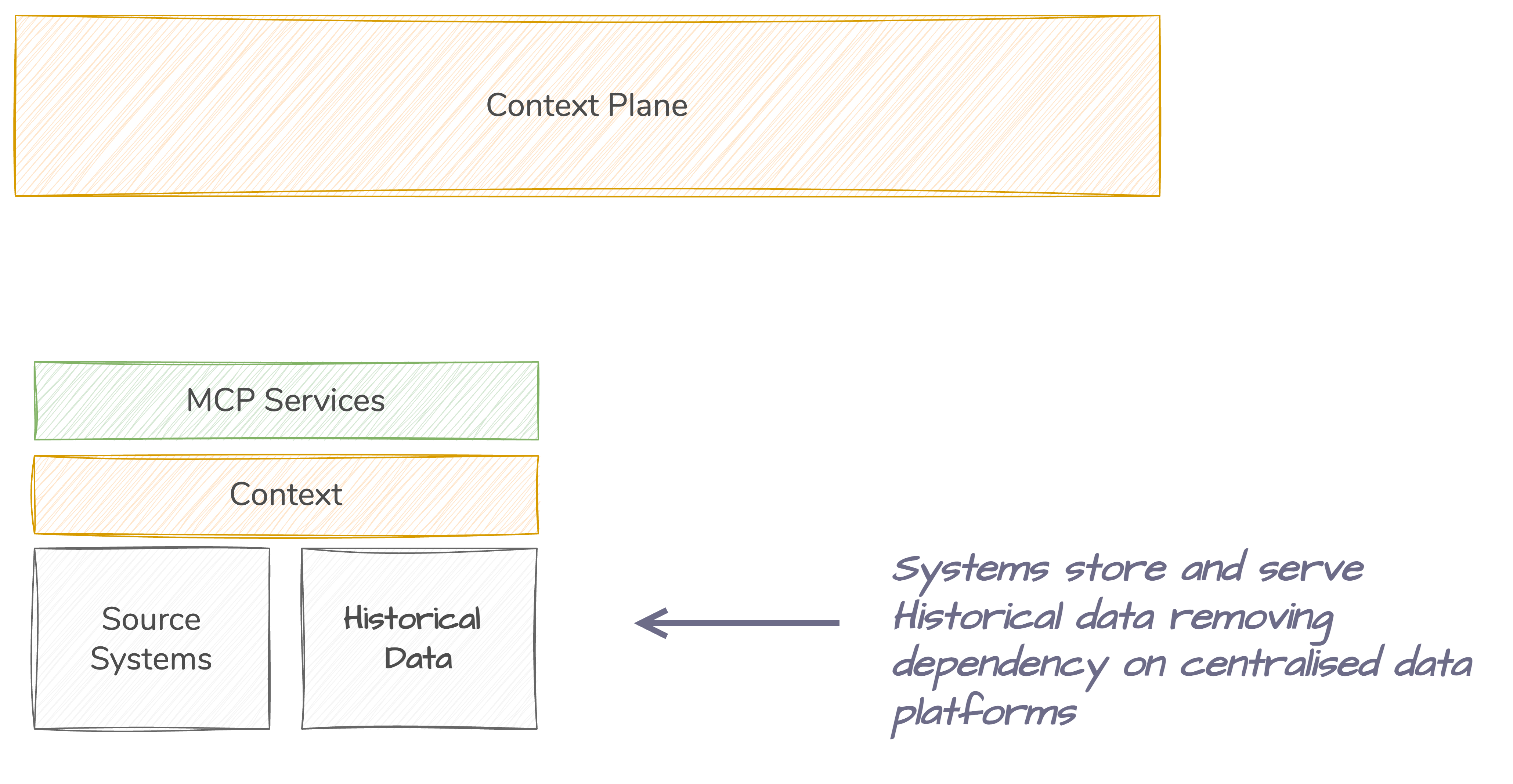
If the source system cannot serve the data needed, for example historical data, then the Agent will need to use the data from the Data Platform.
Source Systems will be forced to start storing Historical data to serve Agents directly.
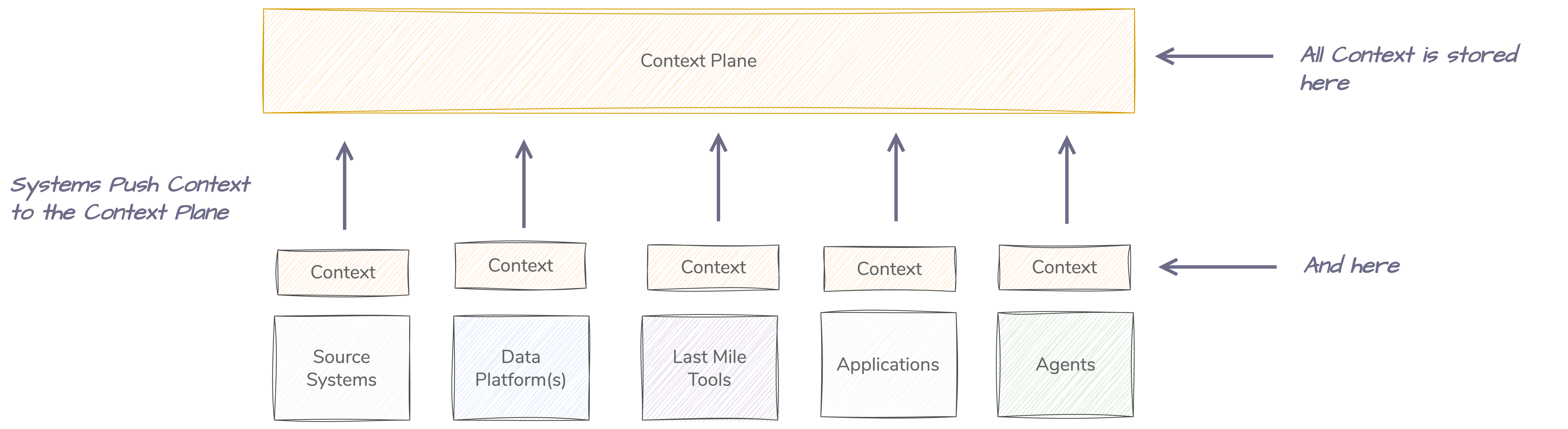
The Context Plane will provide a single pain of glass for all Data Context held by every system, so the Agents can talk to one place.
The Context Plane will receive Context from the Systems, not harvest it. The Systems will Push the Context to the Context Plane. This will remove the need for the Context Plane to have to create an Pull pattern / adapter for every System in the world.
Or the Context Plane will operate under a Federated / Virtualised pattern where it doesn’t hold any Context but can point the Agents to the Systems Context so they can access it directly.
There needs to be a single language for Context, aka the equivalent of SQL, this is unlikely to happen as the data domain can never agree, and vendors like to make their own standards to create lock-in and a “moat”.
The Context Plane will not provide Orchestration or Execution capabilities, Agents will talk directly with the MCP services for the relevant Systems to execute its task.
Agents will either be Orchestrated following a “Direct Graph” pattern or a “Pub/Sub” / “Fire and Forget” / “Mesh” pattern.
AI Agent interaction patterns
Next I start to think about some of the more detailed pattern diagrams to refine my thinking. I find thinking using maps helps me identify the underlying patterns.
Centralised Context Plane
Context is Pushed from each System to the Centralised Context Plane where it is stored.
Federated / Virtualised Context Plane
Context is Pulled from each System by the Federated Context Plane as and when it is needed.

Historical data at Source
Systems stores Historical data, either as part of their primary data store, or as a companion data store. This is managed by the the System Team/Owner/Vendor not by a seperate Data Team / Platform.
Agent Execution via Systems MCP Service
The Agent communicates with the Context Plane to find out where the data it needs lives, and to understand the Context of that data. It then executes directly via the Systems MCP Services.
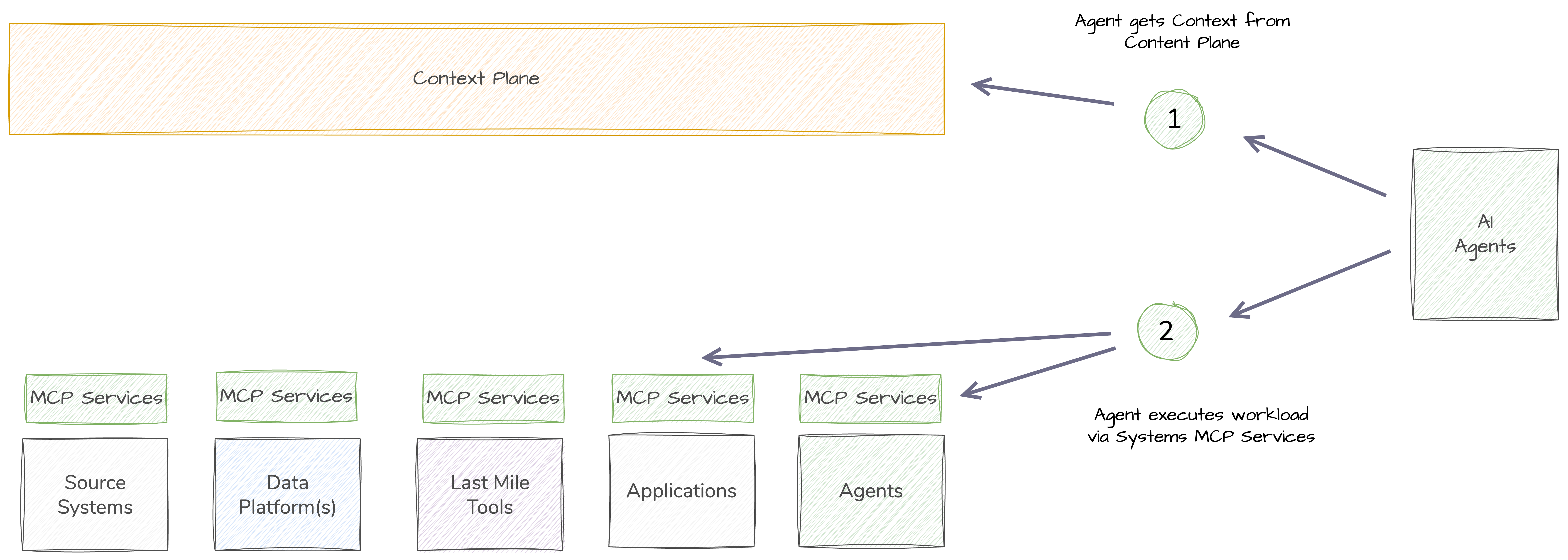
I can see a raft of alternative patterns for this one, centralised MCP Services for execution for example.
Agent Execution via Centralised MCP Service
The Agent communicates with the Context Plane to find out where the data it needs lives, and to understand the Context of that data. It then executes via a centralised MCP Service.

Background to the pattern of the "Context Plane"
First defining our current Context Plane pattern
When we started building the AgileData Platform and AgileData App, Nigel and I agreed on a set of core principles and patterns that we would align to as much as was practical.
One of these was the use of what we called Config (what I now refer to as Context) which should be at the center of everything we would build.
Context is a Pet not Cattle
The Context Plane is where we hold everything we care about that makes our AgileData Platform and AgileData App work, apart from our customers actual data.
We treat both the Context we hold and the Customers data we hold as Pets, and we treat everything else in our Platform as Cattle.
We generate, deploy, execute and destroy code at will. We automate the generation of all code from the Context we hold.
Context drives our App and our Platform
For example everything displayed on our Data Catalog screen is stored in our Context Plane, and then rendered in the AgileData App as needed.

The Concept, Conceptual, Logical and Physical data models are stored in the Context Plane and again rendered in the AgileData App, or used as part of our DataOps processes as and when required.
We define and hold Core Business Concepts, Detail for those Concepts and Core Business Events as the core “entities” in our Context Model.
Concepts, Details and Events are the semantic language we use as part of our Context Language.



We hold the relationships of how Core Business Concepts relate to Core Business Events in the Context Plane.
Which allows us to render and explore a “Graph” view of these relationships in our App.

For those old school of us, we also render these relationships as Bus Matrix in our App. Out Context Plane allows us to render the same Context in any visualisation or Map format that helps simplify complex data tasks.

Our version of Data Quality (Trust Rules) and Observability (Notifications) are again stored in the Context Plane and rendered / used as needed.


Context drives the generation of our code
Our version of Data Transformation logic (Change Rules) is you guessed it, stored in the Context Plane and then used as and when required.





If you perused that last series of screenshots you will see we actually hold surface the Change Rule logic in multiple languages, we surface it via the UI notebook style, we surface it as form of a Gherkin script and we surface the SQL that it is generating to load or transform data in Google BigQuery.
These are all dynamically generated from the Context stored in the Context Plane for each Change Rule we hold. We have defined it once and we can render it in many different ways, many different languages and for many different use cases.
Some people call this a table driven pattern, a metadata driven pattern or a model driven pattern etc.
Orchestrate via dynamic manifests based on Context
To orchestrate the execution of the Data Transformations (Change Rules) we of course build out a Directed Graph to run them in the order they need to be run, and to honour the dependencies they need to honour.

But this Directed Graph is dynamically generated.
If I go and add another Change Rule, it is stored in Context Plane and the next time I come into this screen it will be dynamically rendered including that rule.
When a new record turns up in a table on the left, it will trigger a bunch of steps.
The Context Plane will be queried to see all the Change Rules that are dependent on that data.
The Context Plane will be queried to find the dependencies between the Change Rules that will run, and tables they will load.
A “Manifest” is created to describe what Change Rules need to run.
The SQL code for each relevant Change Rule will be generated from the Context stored in the Context Plane about that Change Rule
The code will be submitted to run using a Pub/Sub model, in parallel.
When all the code has been successfully run, the code and the manifest will be destroyed. (We do hold a copy of the code that was executed in our Audit Vault, so we can always view what was run when).
The latest Observability and Trust data will be stored in the Context Plane.
As we hold the Context of how every physical table (Tile in our language) relates to every other table (Tile), via these Data Models / Change Rules, we can easily show all the dependencies (Related Tiles) for a specific table (Tile), when viewing the Context of that table (Tile).

This includes the relationships for both the Data Model. i.e for this Concept of “customer” we hold these Details, and that Concept of “customer” is part of these four Events, as well as the relationships for all the Change and Trust and Consume rules that the “customer” Concept is part of, i.e this Detail tile is loaded by this Change Rule and validated by these Trust Rules.
Multiple languages to create Context
You can create new Context in the Context Plane via the AgileData App UI, or you can use the API’s to create the Context.

It would be relatively simple to allow the creation of the Context in yet another language, for example by uploading YAML files.
(Fun fact the first interface we had to create Context was Google Sheets!)
One set of Context to rule them all
So you can see how the Context we hold on in our Context Plane is the thing that drives everything our AgileData Platform and AgileData App does.
Context is first and powers everything that happens
I know what you thinking, this sounds a little bit like a data catalog, or a metadata repository.
But heres the thing, data catalogs run by sucking on the Data and Metadata exhaust.
We treat Context as the fuel that powers everything we do.
You cannot run anything if Context does not exist for that thing.
I cannot create a data catalog object, I cannot create a table, I cannot create code or run it, without it existing in the Context Plane.
I first create the Context and then the AgileData Platform then does all the other horrible and complex data work for me.
Its about more than just data and code
As you would expect of any mature data platform, we have added “Data Management” and “Data Governance” capabilities over the years where we found them useful.
One of those is the ability to store the Context needed to render a “Data Dictionary”.

But we are still missing a lot of useful Context
We only build things in our AgileData Platform and AgileData App, when they save us time or automate something we hate doing.
The Data Dictionary feature was built so we could find fields we needed to find by searching all the Context of all the data we hold for a customer.
There is some other Context we know will give us value that we have yet to add.
Things like Context typically related with Business Glossaries, Metric Layers/Engines and Semantic BI Layers to name three.
I believe they are all part of the Context that is needed in a Context Plane to make it useful for AI Agents.
"Context Plane" not Context Layer
Plane not Layer
As I have been iterating and experimenting with my ideas and language for the “Context Plane” I initially started talking about the “Context Layer”.
New Semantic BI Layers for Old
But I found that as soon as I mentioned the term “layer” people from the data domain (and others from other domains) immediately thought like this:

Effectively the Context Layer was seen as the equivalent of a Semantic BI Layer of old. Something that provides Context of the data in the Centralised (or federated) Data Platform to the Last Mile, AI tools and AI Agents.
But to get to the data in the source systems it infers the AI Agents have to traverse through the Data Platform, which is not the pattern I envisage.
How I currently think of “Planes”
Here is a simplified version of the AgileData App and AgileData Platform architecture diagram for how we leverage the Google Cloud Platform infrastructure.

As you can see I tend to think of Control Planes as being horizontal rather than vertical objects on my diagrams.
The “Context Plane”
So my current thinking is the diagram should look something like this:
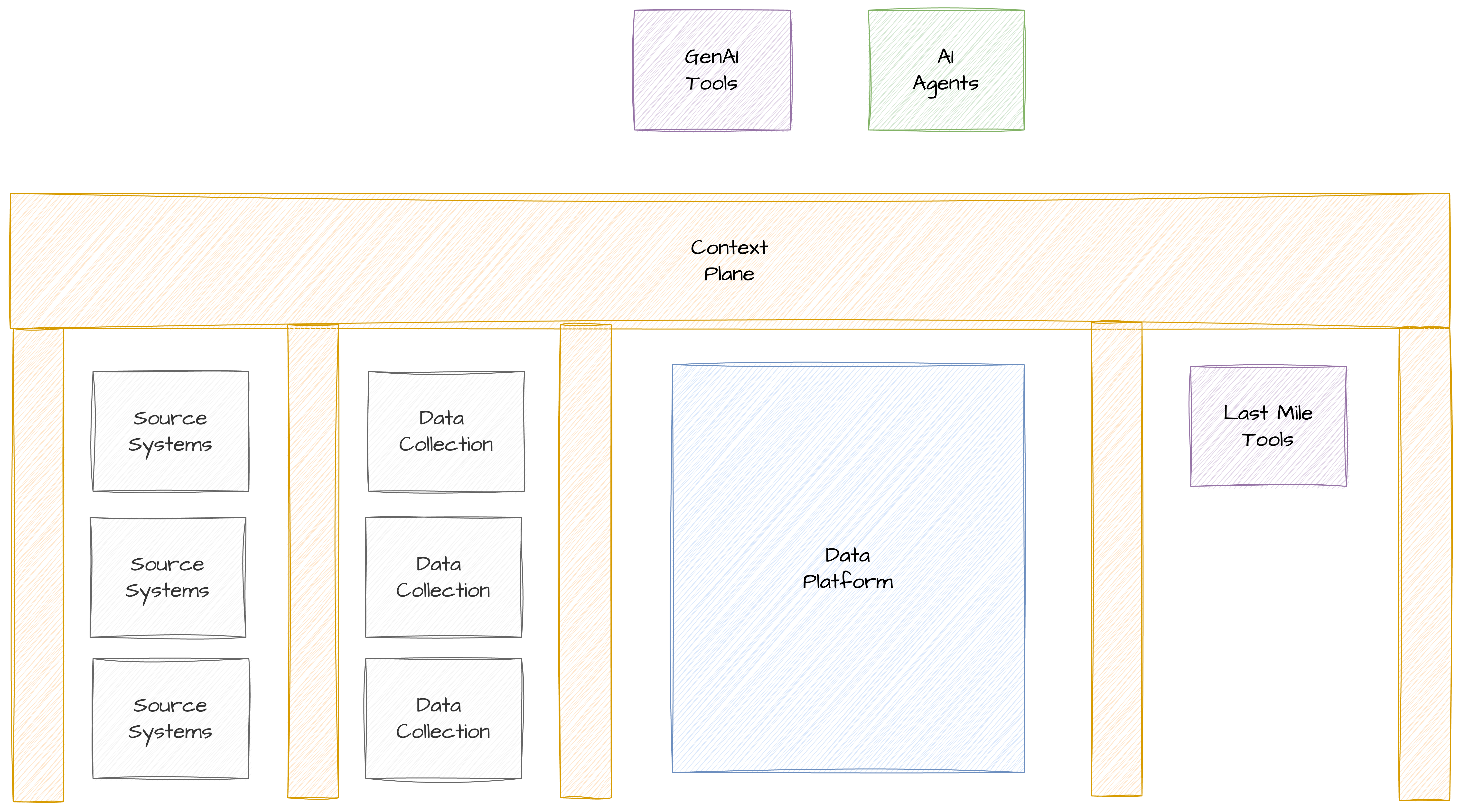
The “Context Plane” should provide the context for everything in the organisation that stores data. And it should allow AI Agents and GenAI tools.
The “Context Plane” should also be the thing a system or a set of tools/technologies accesses to communicate with another system or set of tools/technologies.
To be accurate I should I should have put the orange Context box between each of the Source Systems and Data Collection boxes but I didn’t want to complicate the diagram.
Things in the "Context Plane"
How I think about the things that need to be in the "Context Plane" to power "AI Agents"
“Context” of this post
I often find writing helps me coalesce and refine my thoughts when new patterns start to emerge, but aren’t very clear yet.
So this article is a brain dump / train of thought continuation of the architecture needed to have one Context Plane to rule them all, as part of a proposed “AI Data Stack”.
This article provides an overview of the things or metadata I think should be included in the Context Plane as part of a new “AI Data Stack”.
The “Context Plane”
My current thinking is the architecture diagram for the “Context Plane” should look something like this:
Things stored in the Context Plane
So with that context for how I currently think of the “Context Plane” lets get into the meat of this article, of what I think should be stored in that plane.
I have worked in the data domain for over three decades. The data patterns and the data terms I regularly use I have learnt over those decades. I find them very difficult to unlearn.
As somebody mentioned to me lately I am haunted by “the Ghost of Data Past”.
But also there is a recurring pattern where people seem to invent a new term for a pattern that has been around for decades (medallion data layered architecture anyone), so the patterns of the past do have value.
(and yes I realise the dichotomy of me talking about “Context” not “Semantics” in the same article where I point the finger at the “Medallion Architecture”)
So with all that said, let me use the data components of the past to frame what we need to hold and surface via a “Context Plane” to support what a “AI Data Stack” future might look like.

I originally thought of the boxes in the “Context Plane” as components, things with clear boundaries.
But as I started to try and define the descriptions for each of these components with clarity, and how they could be used by the AI Agent, I realised that I don’t have that clarity, yet.
I can’t clearly articulate the boundary of some of the components as they clearly overlap, or hold things that are subsets of another components.
So I iterated the focus of this article to be describing the things, and try and create an abstracted version of those things that do not overlap.
This is deffo a train of thought article, the journey is as important as the final destination.
Business Glossary
The Business Glossary stores a list of agreed-upon definitions for organisational terms.
This holds a list of plain-language descriptions and aliases that standardise terminology across stakeholders, ensuring consistent interpretation and usage of key terms such as ‘Customer’, ‘Order’, or ‘Churn’.
Core Business Concepts
Core Business Concepts stores the primary things (‘entities’) an organisation manages or counts. This includes concepts such as ‘Customer’, ‘Product’, ‘Order’, and ‘Payment’.
This holds a list of the definitions and identifiers for the Core Business Concepts.
It contains a subset of the terms that exist in the Business Glossary and forms the foundation of the organisations data design.
This describes a list of “things”.
Core Business Processes
Core Business Processes stores the major operational workflows, events or life cycles (‘relationships’) within an organisation.
This holds a list of the interactions between Core Business Concepts, representing relationships such as “Customer Places Order” and “Customer Pays for Order”
This also holds the sequence of activities or states that Core Business Concepts transition through, such as invoice approval or support resolution (which I call “Administration Processes”).
This describes ‘relationships’ between “things”.
With the current definition its not going to hold hierarchy relationships Product Category > Product, as that relationship is not part of a relationship between Core Business Concepts, nor is it a state change within a Core Business Concept.
Something to be resolved.
Conceptual Data Model
The Conceptual Data Model stores a high-level map or diagram that provides an abstraction of the organisation’s data design.
This holds information that outlines the Core Business Concepts, Core Business Processes the other relationships between Core Business Concepts in a platform-independent format and without specifying implementation details.
The Conceptual Data Model can also hold the objects that generate the Diagram, so overlaps with the Core Business Concepts and Core Business Processes.
This describes “things” and the ‘relationships’ between “things”
Logical Data Model
The Logical Data Model stores a more detailed map or diagram that provides Details (‘attributes’) that are part of the organisation’s data design.
This holds information that outlines the Core Business Concepts, Core Business Processes / Relationship’s in a platform-independent format.
It also holds the Detail (‘attributes’), that are related to a Core Business Concept, in a platform-independent format
This describes the Details of “things”.
Physical Data Model
The Physical Data Model stores a technical implementation view of how the organisation’s data is stored and accessed within a specific system.
This holds information on the the physical structures such as tables, columns, data types, indexes, partitions, and naming conventions used in the data platform.
It is derived from the Logical Data Model but adds system-specific optimisations and constraints.
It overlaps with the Logical Data Model by representing the same Core Business Concepts and their Details but also includes physical performance and deployment details that are specific to the technology used.
This describes how to implement the “things”, their ‘relationships’, and their Details.
Data Contracts
Data Contracts store the expected structure, quality, and behaviour of data exchanged between systems, or components. They describe formal agreements between a data producer and a data consumer.
This holds information such as schema definitions, required fields, data types, validation rules, and guarantees such as update frequency, timeliness, or completeness.
It overlaps with the Logical Data Model and Physical Data Model by referencing the same attributes and structures, but focuses on expectations and enforcement rather than storage or modelling.
This describes the Rules that govern the movement of the data.
Data Dictionary
The Data Dictionary lists and describes the metadata for data fields used across the organisation’s data assets.
This holds a list and information for data fields, such as field names, data types, descriptions, allowable values, formats and default values.
It overlaps with the Business Glossary. Logical and Physical Data Models by documenting the same ‘attributes’.
This describes how “things” and their Details were implemented.
Data Profiles
Data Profiles provide statistical summaries and characteristics of the data physically stored.
This holds data such as minimum and maximum values, distribution ranges, cardinality, null counts, uniqueness, and data type conformity.
They overlap with the Data Dictionary (by describing the same fields) and with Facts (by profiling the raw values captured).
This describes the observed characteristics of the Details of “things” and ‘relationships’ between “things”.
Transformation Logic
Transformation Logic stores how raw or source data is converted into a trusted, usable form.
This holds the business rules, mappings, calculations, filters, joins and aggregation logic or code applied to reshape data.
It may reference fields defined in the Logical or Physical Data Models and rely on terms from the Business Glossary and Core Business Concepts to apply meaning.
It overlaps with Measures, Metrics, Actions, and Information Products by forming part of the logic used to answer questions or trigger downstream outcomes.
This describes how the raw “things”, Details of “things” and the ‘relationships’ between “things” were reshaped into something more useful.
Facts
Facts are raw numerical values stored or sourced directly from systems.
This holds a list of data such as quantities, amounts, durations.
Facts are the foundational inputs used in downstream calculations. They are not aggregated or transformed, but instead represent the atomic, immutable data from systems where that data is first captured.
They overlap with the Business Glossary, Physical Data Model and Data Dictionary where they are described and with Measures and Metrics, which are derived from them.
This describes the raw numerical values about “things”.
Yes I know this is a different definition from the typical definition of a “Fact” from the Dimensional Modeling pattern, but I am trying to abstract these things from specific data modeling or technology patterns.
Measures
Measures are standardised aggregations of raw Facts.
This holds the logic or code for calculations such as “total revenue”, “count of orders”, or “average order amount”, typically derived using functions like sum, count, min, max, or average based on a defined Fact.
They overlap with Facts (as their source), Transformation Logic (which defines how they are calculated), and Metrics (which may use them as components).
This describes aggregated values about the Details of “things”.
Metrics
Metrics are calculated formulas that combine Measures, Facts, or other Metrics to express business performance or operational efficiency.
This holds the logic or code for calculations such as “average revenue per customer”, “conversion rate”, or “churn percentage”, typically involving arithmetic, ratios, or conditional logic.
They overlap with Measures (which they reference), Transformation Logic (which defines their formulas), and Business Questions (which they help answer).
This describes derived insights from aggregations of the Details of “things”.
Business Questions
Business Questions are predefined or commonly asked queries that reflect specific decision-making needs within the organisation.
This holds a list of the questions that have been asked before such as “What is our monthly churn rate?”, “Which products are underperforming?”, or “How many new customers joined last quarter?”
They overlap with Metrics (which may be the answer), Transformation Logic (which defines how to calculate the answer), and Information Apps (where answers are delivered).
This describes the repeatable questions asked about the “things”, Details of “things” and ‘relationships’ between “things” to support decisions to take action.
Actions
Actions define the decisions, tasks, or system behaviours triggered as a result of answering a Business Question.
This holds a list of actions that have been taken in the past or need to be taken int he future.
It also holds information of the mappings between specific Business Questions and the Actions they enable, such as “Identify outstanding support tickets” and “resolve outstanding support tickets,” or “Identify Customers who havent placed an order in the last 6 months” and “Offer discount to Customers to reduce the rate of customer churn.”
They overlap with Business Questions (which initiate them), Information Apps (where they may be launched), and Core Business Processes (which they may automate or influence).
This describes the decisions and actions we take based on what we know about the “things”, Details of “things” and ‘relationships’ between “things”
Information Apps
Information Apps are curated outputs that present data and information in a usable form to answer Business Questions and support Actions.
This holds lists and information about dashboards, reports, visualisations, datasets, APIs, data servies, and user interfaces that package answers to Business Questions and trigger related Actions.
They overlap with Business Questions (which they answer), Actions (which they enable), and Facts, Metrics and Measures (which they visualise or expose).
This describes the delivery mechanism that provides access to what we know about the “things”, Details of “things” and ‘relationships’ between “things”
Fragmentation and Overlaps
I realised as I wrote this one of the major problems is deffo “the Ghost of Data Past” and specifically the fragmented set of data technology and tools that I have used over the years. These set of data technology and tools helps define the architecture and language I use, and also influences the patterns I applied to list the things that should be stored in the ”Context Plane”.
I have ended up using these technologies and tools to define the things that are needed in the “Context Plane” and also to define boxes or boundary around things.
The problem I hit is when I use these standard languages / boundaries from the data domain for those things then I get overlaps, there are things that are in within / across multiple boundaries.
For example Core Business Concepts are held/described within both a Business Glossary and a Conceptual Model.
An example using a Metric
Metrics are a part of a Business Question, but also defined in both a Metrics Layer / Tool, Business Glossary and potentially a Data Dictionary.
Lets look at an example of the overlaps in more detail using a specific Metric ‘Active Users’.
Metrics:
'Active users' is the number of people who engaged with our site or app in the specified date range.
An active user is any user who has an engaged session or when Analytics collects:
* the first_visit event or engagement_time_msec parameter from a website
* the first_open event or engagement_time_msec parameter from an Android app
* the first_open or user_engagement event from an iOS app
The user is considered an active user as soon as the user_engagement event is detected within a second.(Source: https://support.google.com/analytics/answer/12253918?hl=en)
Business Questions:
"The Number of Active Users who accessed our Website last month."
"The Number of Active Users who accessed our App last month."
The Metrics Layer often holds the relationship the Metric has with the Core Business Processes, the Business Glossary often does not.
Yaml Metric Definition in a Metrics Layer tool:
views:
- name: active_users
description: "14 days rolling count of active users"
includes:
# Measure
- users.rolling_count
# Dimensions
- users.is_paying
- users.signup_date
- company.name(Source: https://cube.dev/blog/introducing-views)
Business Glossary:
Active user
Active users are the people who currently use your product. A user who becomes inactive may have churned.(Source: https://posthog.com/docs/glossary)
As you can see there are overlaps in what we define for the Metric of “Active Users”, depending on which traditional data component we define it in.
Removing the Boundaries and Overlaps
When I get stuck with a problem like this I find the key is to keep breaking it down into smaller and smaller things until I get to a list of atomic things that are unique.
Here is where I have ended up with two different languages I can use so far:
(compiled with some help from my ChatGPT friend using the above as the input, and then the human iterated it)
The list of Context we store
Or put another way the things we store.
Business Terms
Agreed-upon definitions and aliases used across the organisation (from the Business Glossary).
Core Business Concepts (entities)
The primary entities the organisation manages or counts (e.g. Customer, Product, Order).
Core Business Processes
The workflows, events, or life cycles that define how Core Business Concepts interact and change over time.
Conceptual Relationships
High-level, platform-independent relationships between Core Business Concepts.
Details (attributes)
Descriptive details of Core Business Concepts, such as name, status, date of birth (from the Logical Model).
Field Metadata
Technical descriptions of fields, such as data types, formats, default values, and allowable values (from Logical Data Model and Data Dictionary).
Physical Structures
Tables, columns, data types, and indexes used to implement data in a specific platform (from the Physical Model and Data Dictionary).
Data Rules and Expectations
Contractual schema definitions and guarantees that govern how data is exchanged and validated (from Data Contracts).
Statistical Profiles
Observed characteristics of data, including distributions, cardinality, and null rates (from Data Profiles).
Transformation Logic
Business rules and operations that convert raw data into usable outputs (e.g. mappings, joins, calculations).
Raw Numerical Values
Source data captured as facts, such as quantity, amount, or duration (from Facts).
Aggregated Values
Summarised calculations based on raw numerical values (from Measures).
Derived Metrics
Formulas combining multiple measures or facts to express performance or ratios (from Metrics).
Business Questions
Repeatable questions that drive insight and inform decisions (from Business Questions).
Actions
Operational steps or decisions taken based on answers to Business Questions.
Delivery Interfaces
Mechanisms that present data and enable interactions, such as dashboards, reports, datasets, and APIs (from Information Apps).
The types of Context we store
Or put it another way, how it is stored.
Lists
Repeating sets of labelled items.
Examples:
– List of business terms (Business Glossary)
– List of fields (Data Dictionary)
– List of metrics, measures, concepts, questions, or actions
– List of attributes, rules, or processes
Definitions
Text-based descriptions that explain meaning, purpose, or intent.
Examples:
– Term definitions
– Field descriptions
– Action explanations
– Business question phrasing
Identifiers
Unique keys, codes, or labels used to reference or join data.
Examples:
– Concept identifiers
– Field names
– Relationship keys
Relationships
Structured mappings between two or more things.
Examples:
– Concept A interacts with Concept B
– Concept A, Concept B and Concept C are involved in Process A– Detail belongs to Concept (attribute belongs to entity)
– Measure uses Fact
– Metric uses Measure– Question → Metric → Action
– Term → Concept → Field
Rules / Logic
Outputs produced from raw data using logic or formulas or expressions that define behaviour or constraints.
Examples:
– Validation rules
– Data contracts
– Calculation logic
– Transformation pipelines
– Measures (aggregated)
– Metrics (calculated)
Structures / Schemas
Models that define how things are organised or composed.
Examples:
– Logical/physical data models
– API schemas
– Table definitions
Raw Data / Values
Captured data points or measurements.
Examples:
– Facts (quantities, amounts)
– Timestamps
– Event logs
– Data Profile results
– Data Quality results
Interfaces / Outputs
Representations used for delivery or consumption.
Examples:
– Information Apps
– Dashboards– Reports
– APIs
– Data services
Time to Cross Domains
As I mentioned at the start, my experience and expertise is founded in the data domain.
I think its time to look for help from the other domains, and for this one specifically the Library and Information Sciences domain.
Juan Sequeda posted an LinkedIn article on how he is thinking about metadata/ontologies/knowledge graph/semantic layers. In that article he uses this framing:

I can probably simplify “the List of Context we store” and “the Type of Context we store” above to the Business/Technical/Mapping metadata categories in that diagram.
But Im not sure simplifying it will get me any closer to achieving my goal, I think I need to go down into the weeds a little more to get the clarity I need.
One option to do this safely I think I need to identify a number of use cases where “AI” will use the “Context Plane” and see what I need to provide it to be successful.
Another option is to try and collaborate with an expert from the Library and Information Sciences domain to help add their views and language to see if it gets me to the next step.
The other option is to follow a suggestion Joe Reis made on the Practical Data Modeling Discord,
“As a thought experiment, ask any AI what it needs. It’s very different from what we’ve devised so far”.
Time to have a little think about what the next step in my train of thought for the “AI Data Stack” will be.
Integrating Gemini CLI with the "Context Plane"
Integrating Gemini CLI with the "Context Plane" via the use of a MCP Server
“Context” of this post
I often find writing helps me coalesce and refine my thoughts when new patterns start to emerge, but aren’t very clear yet.
So this article is a brain dump / train of thought continuation of the architecture needed to have one Context Plane to rule them all, as part of a proposed “AI Data Stack”.
This article provides an overview of integrating and using Claude and Google Gemini CLI with the “Context Plane” via a MCP service.
MCP (Model Context Protocol)
The next thing I wanted to understand was how a MCP would work with the current version of the “Context Plane” we have in the current AgileData Platform.
McSpikey
So time to do a McSpikey (experiment) with Nigel. Success for this experiment was to be able to query the AgileData “Context Plane” with tools such as Claude and Gemini CLI.
MCP Server
We are a Google Cloud only platform so we thought that using this MCP server would make sense
https://github.com/googleapis/genai-toolbox
But after some investigation Nigel worked out it would mean a lot of rework, as we would have had to define all the tools and sql queries needed to query Google Spanner, where we store our Context.
Since we already have all those queries defined as part of the AgileData Platform API’s. Nigel discovered that we could just wrap our existing FastAPI endpoints with FastApiMCP and so we implemented that.
In the words of Nigel:
toolbox is just a wrapper for the same transports etc we are using, we just get them from free and dont need to write all the config that it requires … think 5mins to enable compared to hours of
We always like minutes over hours at AgileData and we love the DORO principle (Define Once, Reuse Often)
There were some challenges deploying FastAPIMcCP via Google App Engine, if you want more details on that just ask and Nigel can write up a more technical post on how that went.
Architecture
So we ended up with an architecture that looks like:

Gemini CLI talks to MCP Service
MCP Service calls applicable API (exposed as tools)
API talks to “Context Plane”
Connecting Gemini CLI to MCP server
Its always funny what takes the most time when doing a McSpikey.
When Nigel setup the MCP server he connected to it using Claude, next learning you need to have a paid version of Claude to provide MCP connectivity.
So I though I would use Google Gemini CLI for me.
Next learning, the paid version of Claude makes it very easy to define the MCP connection, you pretty much paste the url for it in.
Gemini CLI not so much, you need to frig around with JSON strings in a settings.json file.
And of course finding the exact structure for that JSON is a pain.
After a bit of trial and error got it working with this:
{
“selectedAuthType”: “oauth-personal”,
“theme”: “Dracula”,
“mcpServers”: {
“MCPServer1": {
“url”: "https://mcpserver1/mcp
}
}
}Lets Get Ready to Rumble
Does it connect?
So first test does it connect to our “Context Plane”?
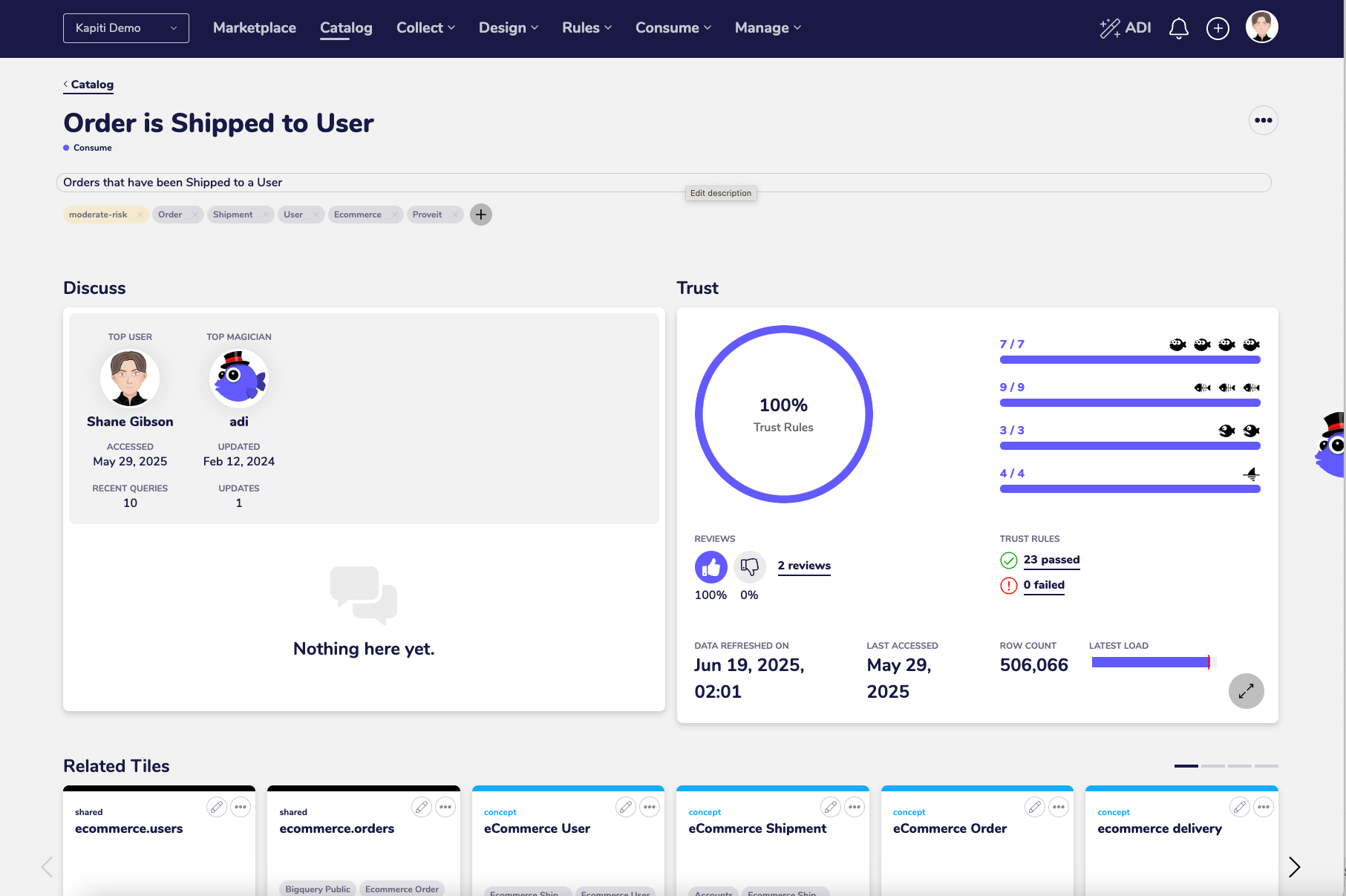
/mcp list
Yup it can see the MCP server and it can see four API end points that we have exposed.
Does it see Context objects?
Next lets test if it can see objects stored in the “Context Plane”
list tile names
Its worked out the correct API to hit to get back a list of Tiles from the Catalog.

And its given me a list of Tile names.
Does it understand Context for those objects?
We run a layered data architecture and the Data Layer is held as Context for the Tiles, not in the tile name etc. So that why im getting multiple Tiles back with the same name.
Lets try to get some Context.
list tile names and their data layer
All good, it worked out what Data Layer the Tiles belong in.
Interestingly we never use the term “Data Layer” in the “Context Plane”, im guessing its picked up the Data Layer from the table prefix or the object type we hold against each tile.

I had assumed we would need to add extensive aliasing of terms in the “Context Plane” to make it find answers to people natural language questions, but given Gemini CLI is backed by the Gemini LLM maybe we don’t.
(This is the value of doing a McSpikey, you discover things you didn’t know, and of course end up with more questions to answer).
Real Life Use Cases
I have been asking people at the coal face for use cases they constantly hit where they think accessing the “Context Plane” may reduce the complexity of the data work they do.
Im looking for use cases that are more than the usual “text to SQL” use case everybody now has as table stakes in their product.
Get Data Catalog Tiles
We have already proven we can connect and get Catalog Tiles using Gemini CLI.
But I am a GUI by default kinda guy and so for that use case I would just use the Catalog search screen in the AgileData App.
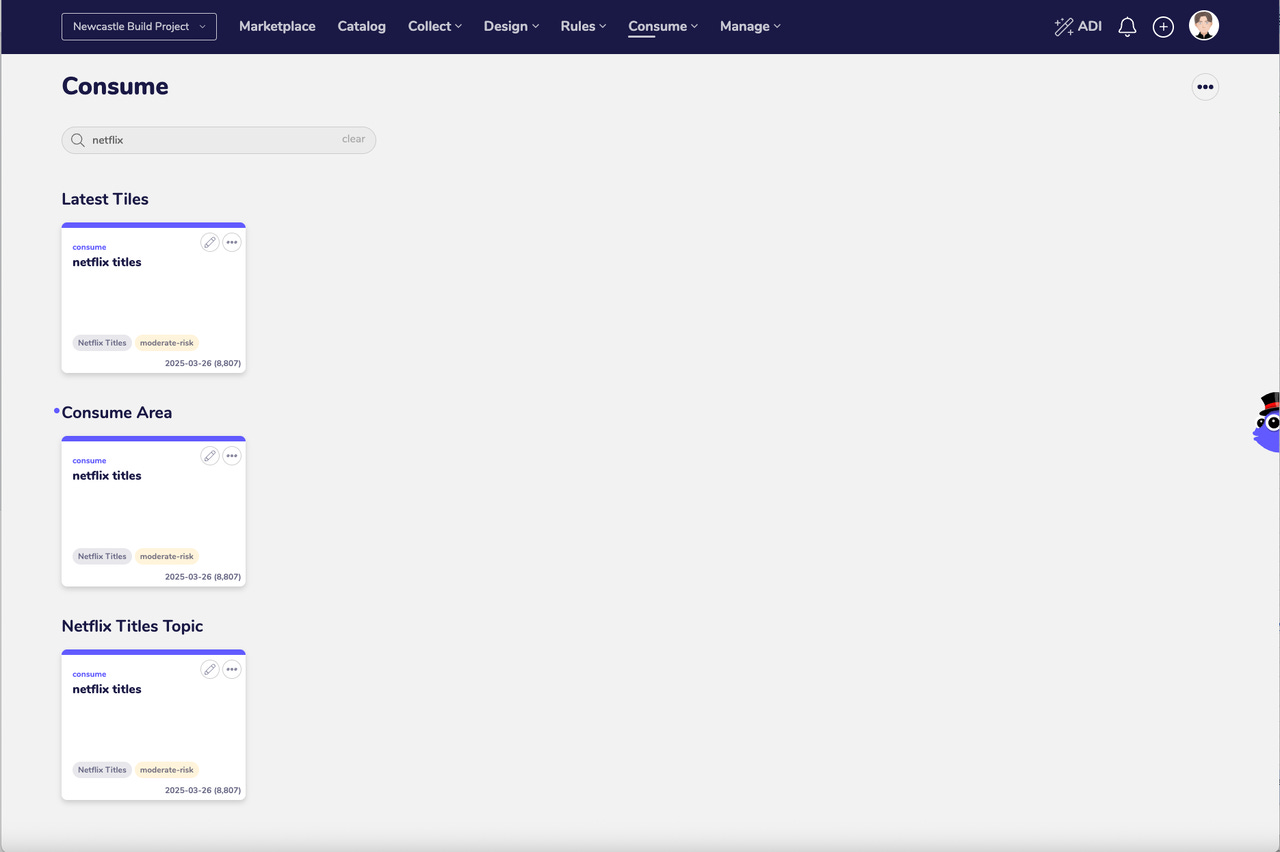
A couple of clicks and i’m done, no need to type lots of words.
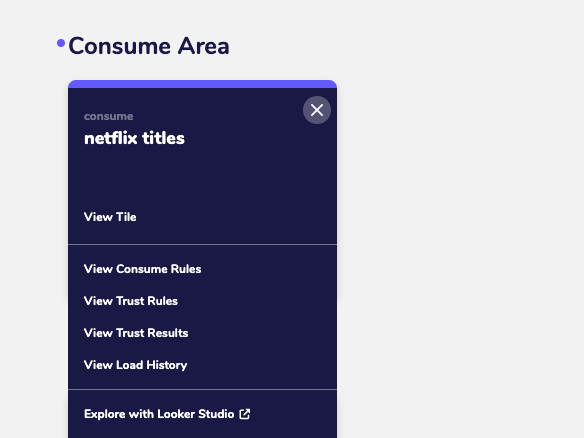
Ask a question, get an answer, Context provided for me
The challenge with the App approach is I know that I need to search for Consume Tiles if I want to use the data on a Last Mile report. A new user would not.
So lets try that scenario by asking:
I need to use Netflix data in the report I have to create for the boss
Again its using the concept of our Data Layers to understand that data in the Consume layer should be used in a report.
Given we have provided no RAG or Prompt reinforcement on our Data Layer Architecture I wonder if its because we use clear terms like “Consume” rather than “Gold” that is helping the model.
Its also come back with a follow up question, lets answer it and see what happens.
details about cast and directorsLooks like its checking the Data Dictionary for the Tiles to see what fields are available.
As an aside there is now finally a reason for us to populate a Description for each Field in the “Context Plane”.

And its come back with the Fields I would need to use for my report.
Its also asking if I want it to help me build that report.
show me the data
It recognises that it has no MCP service to access data or run a query.
One of the features we built in the AgileData App ages ago was the ability to click on a Catalog Tile and open the data directly in Looker Studio, as a very quick way to explore the data via a GUI.
Gemini CLI has understood that from the “Context Plane” and look like it found the relevant Looker Studio url to open the data I need in Looker Studio.
Lets cut and paste that url ….
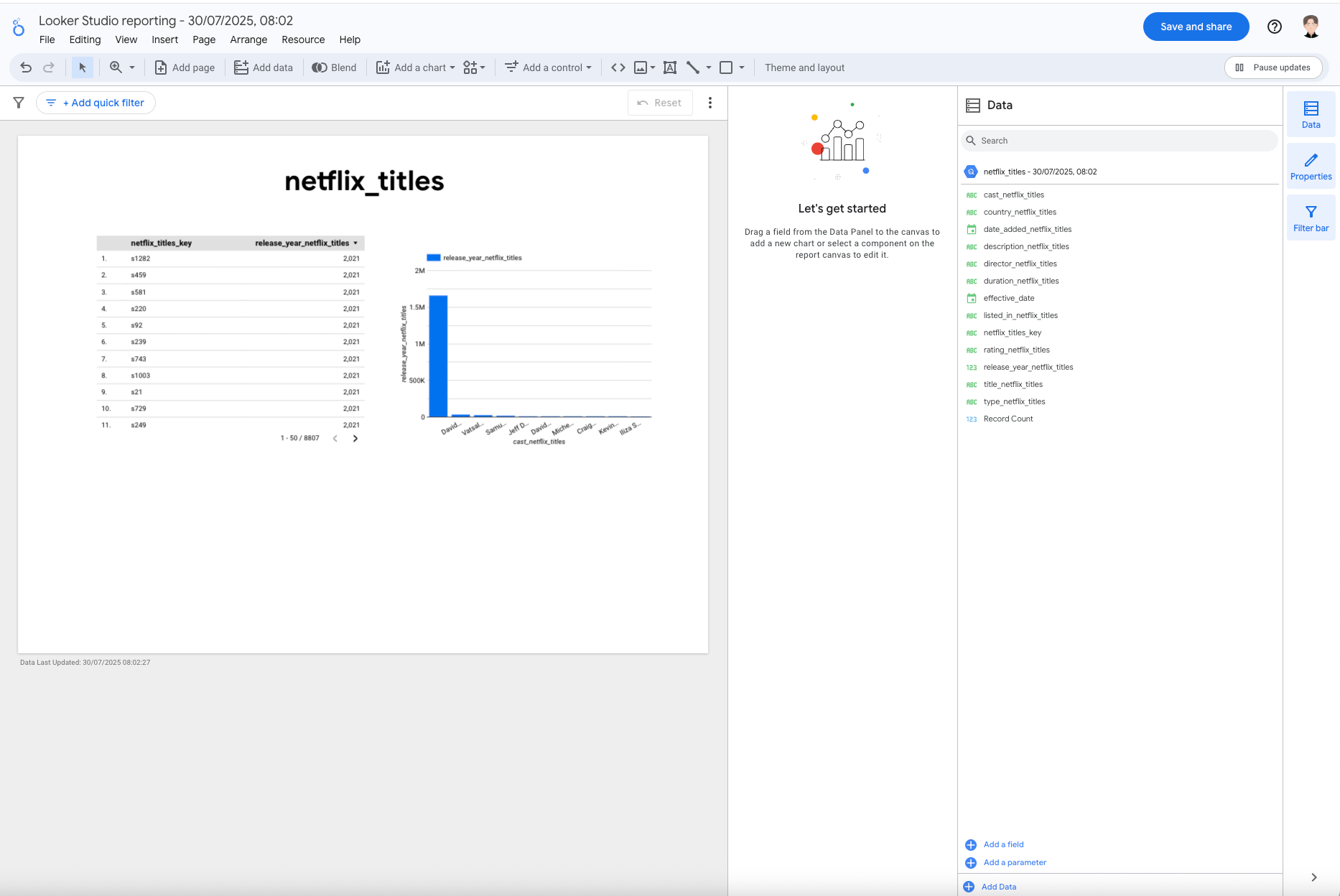
Yup thats exactly what it has done that was unexpected but magical.
Wonder if I could get it to rewrite that url to only include the Fields I am after, that is a question for another day.
Show me the impact of a change
The second real life use case I got given was to see if it would help streamline the process of understanding the impact of the changing a Field somewhere in the data pipeline flow.
i need to update the field type for the director for the netflix tile what do I need to worry about impact wise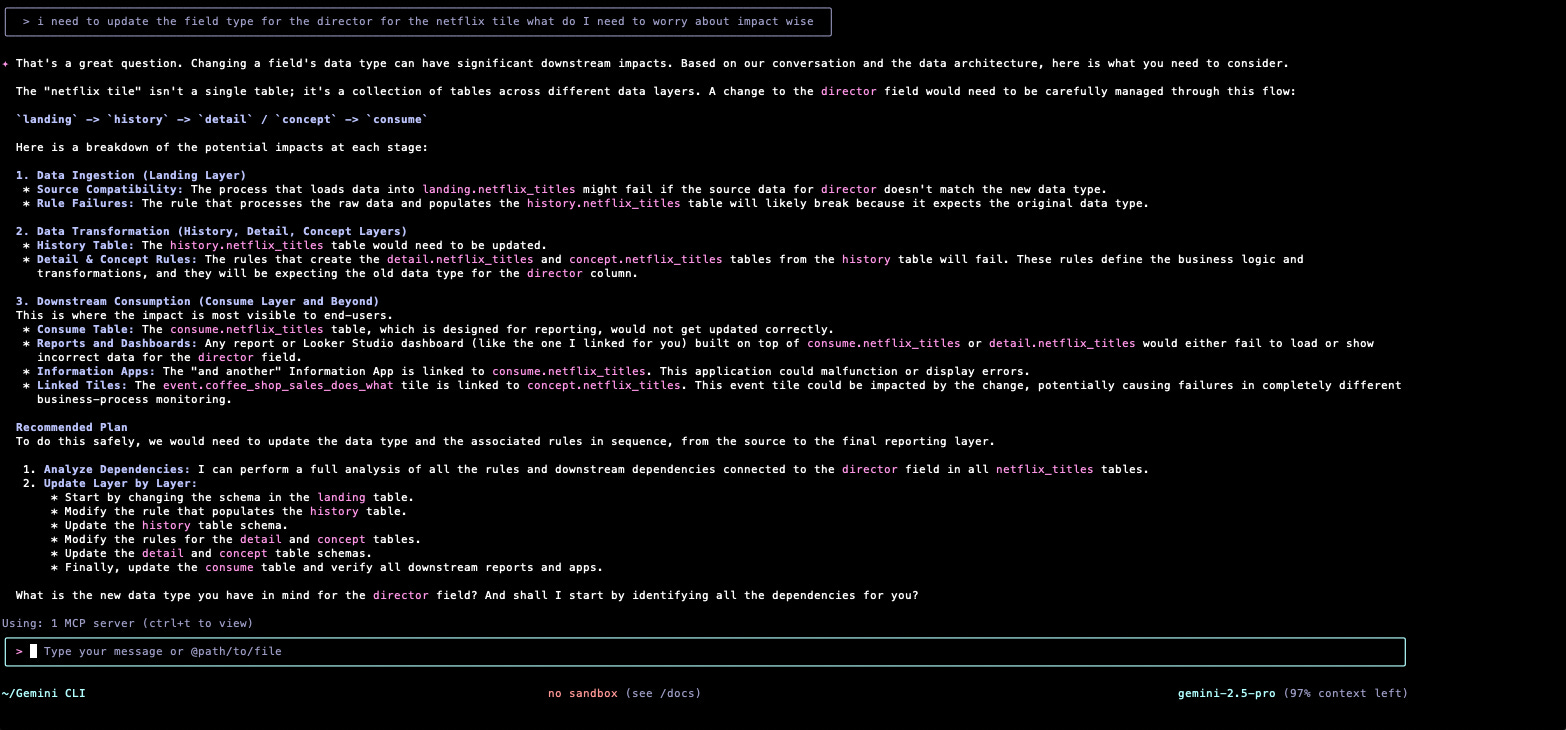
It did a pretty good job of understanding the flow of the data and transformation logic for that Field.
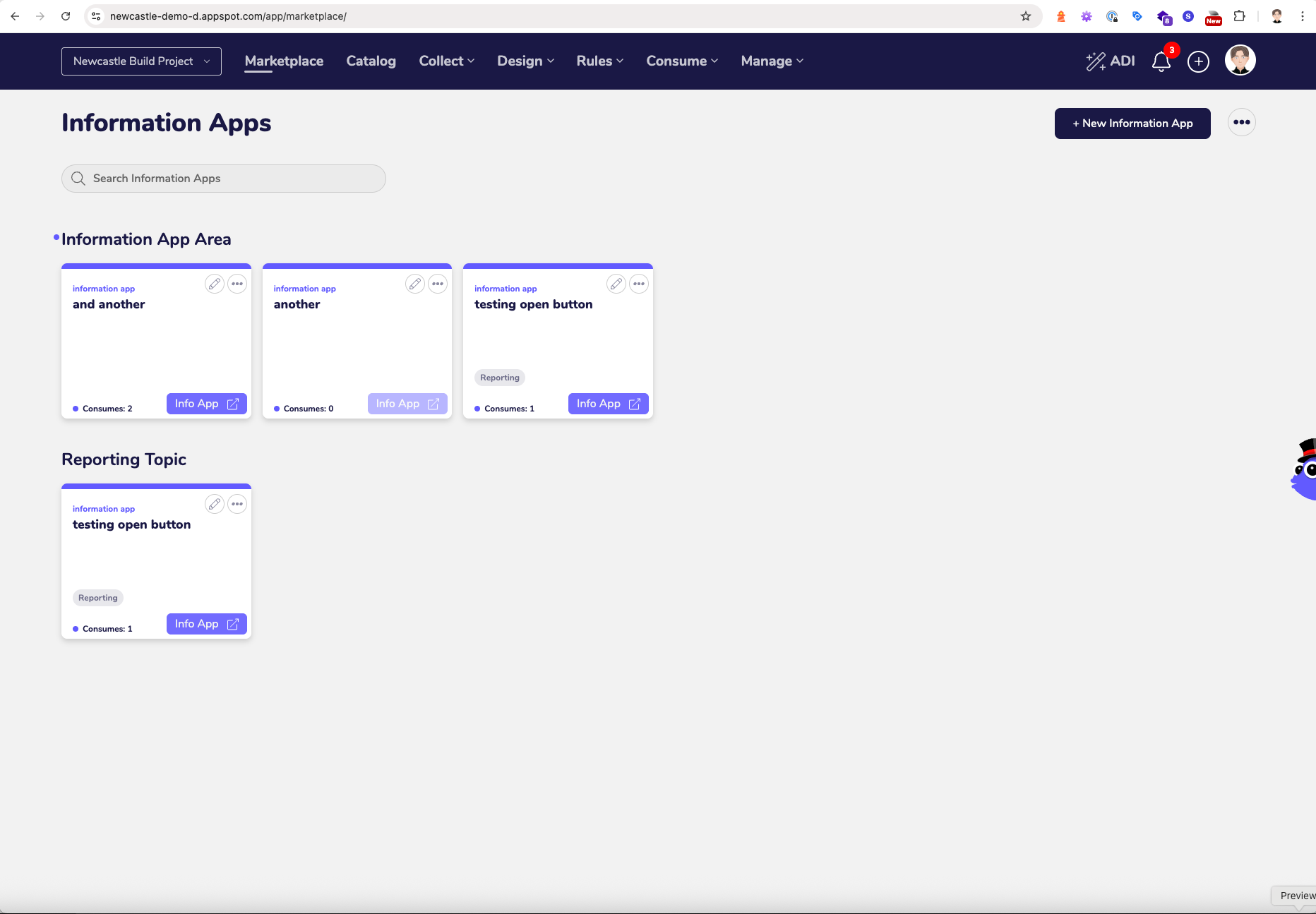
Because we store the Information Apps that are accessed by Information Consumers in the “Context Plane” and we link tose to the Consume Tiles they consume it also picked up the Last Mile objects that may break and impact our Information Consumers.
One question I have is how it determined the lineage for this data from the four API services we gave it access to, as we did not give it access to the Data Map (lineage) API service.
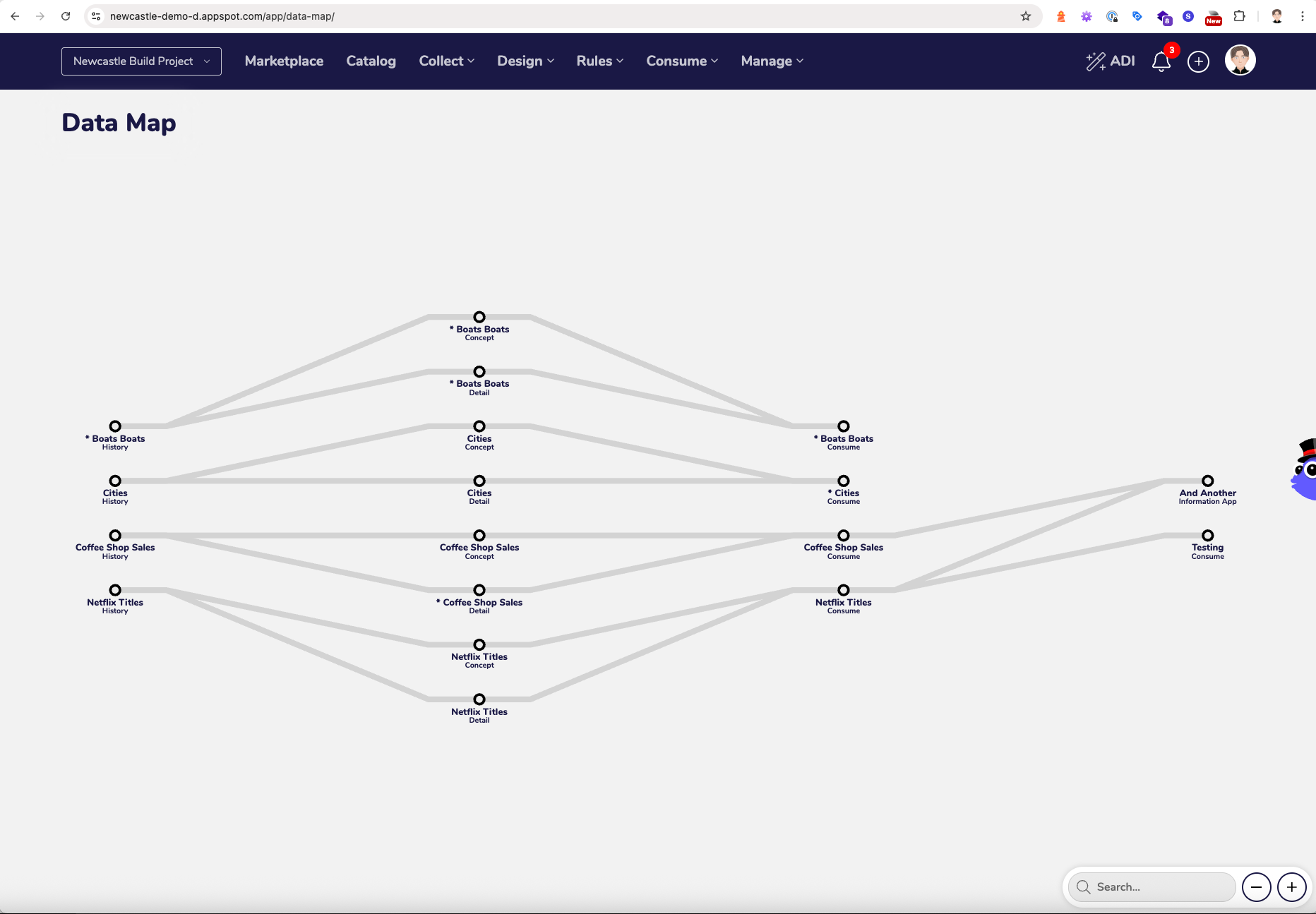
Im guessing it stitched it together from the Change Rules.
Another question to be answered. I am going to have to figure out how to get Gemini CLI to show me what MCP services it using to understand the process more. Task for another day.
So in Summary
Colour me impressed!
Wood from the Trees
Still a way to go before I have a coherent set of Patterns that I can Coach / Mentor / Teach somebody else for the “Context Plane”, and the “AI Data Stack” or present as a robust Architecture map.
But as I have already said, writing my half formed ideas helps me think.
This is really good stuff. Thank you for mapping out these patterns and providing the context needed to understand existing and emerging AI capabilities.